DSM: A Low-Overhead, High-Performance, Dynamic Stream Mapping Approach for MongoDB
In this project, we exploits Multi-Streamed SSD to optimize WiredTiger storage engine in MongoDB. Compared to the original WiredTiger, optimized one imporves the throughput by up to 65% in Linkbench.
For detail, view our [paper].
Multi-streamed SSD
Erasing overhead. Out-of-place updates in NAND flash SSD require a data block (i.e., sector) must be erased before new data are writing on. Erasing a block with all invalid or valid data is fast. The Flash Translation Layer (FTL) just adjusts the mapping table (map logical block address to physical block address). However, with partial invalid blocks, that are blocks have some valid data pages, FTL must copy valid pages to new empty block before erasing the old one. That lead to copying overhead. How to minimize partial invalid blocks?. Multi-streamed SSD was born to answer that question.
Multi-streamed SSD basic. Multi-streamed SSD allows applications from user space or kernel space assigning a stream along with a write or pwrite system call. As the results, all writes with the same stream ID alocated in the same NAND block. If the stream assigning in application is done properly, all pages in the same block will be invalid at the same time. Thus, minize the number of partial invalid blocks.
Stream mapping strategies
Finding the properly stream mapping strategy is nontrivial. It depends on storage engines, file structures, and the applications (i.e., workloads).
File-based stream mapping. One basic mapping approach is assign each stream to file types. Since DBMS accesses to one file type more frequent than other file types, file-based stream mapping reduce the number of partial invalid blocks in NAND flash. However, data fragmentation in one file type is inavictable because DBMS also write one part of a file (hot region) more frequent than other parts (cold regions). Unfortunately, a hot region at this time could become cold region in next couple of seconds. In WiredTiger, for example, during a checkpoint period, WiredTiger write asymmetric on two regions. However, during the next checkpoint, the hold region become cold region and vice versa.
To solve that problem, we propose boundary-based stream mapping that is discussed in next section.
Boundary-based stream mapping. We split one file into two regions and assign each one with a streamID as illustrated in the figure below:
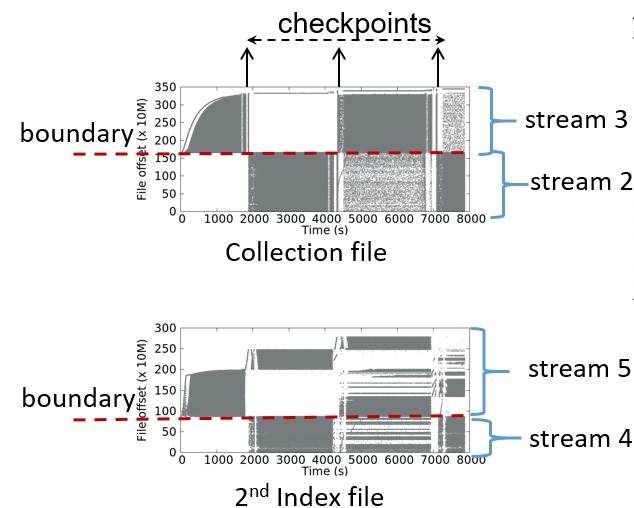
Note that boundary-based stream mapping is specified only for WiredTiger or any storage engine that share similar characteristics. Boundary-based stream mapping works based on the boundary regardless of hotness of regions. In some workloads, regions are not either hot or cold but warm. In those cases, boundary-based is inadequate and data fragmentation in one region still exists. To solve that problem we proposed dynamic stream mapping.
Dynamic stream mapping (DSM). This approach compute hotness values of regions during a checkpoint period and dynamically assigns properly streamID to each region based on its hotness value. The overall process is illustrated in the figure below.

With DSM, we solve the cross-region data fragmentation. Take the privious write pattern as illustration.
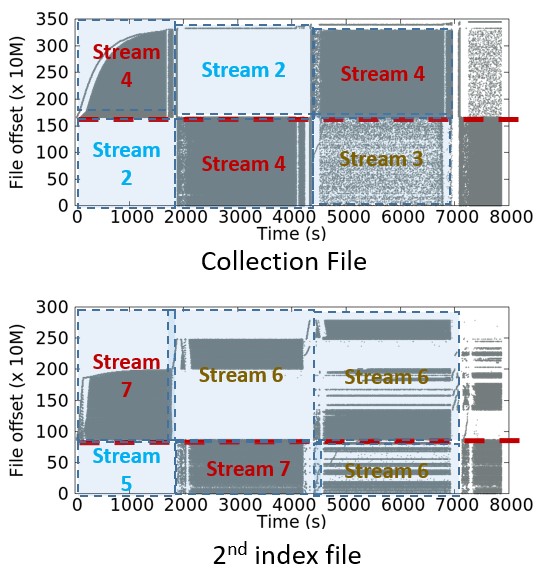
DSM could identify the warm region and assigns different streamID (stream 3) to the hot region (stream 4) and cold region (stream 2).
Experiment
Experiment Settings. For using multi-streamed feature, we modifed Linux kernel 3.13.11 and customized firmware Samsung 840 Pro SSD. We experiment on the server with 48 cores Intel Xeon 2.2GHz processor, 32GB DRAM, Samsung 840 Pro SSD with multi-streamed feature. We implement stream mapping aproaches on the original WiredTiger on MongoDB and set the cache size vary from 5GB to 30GB. We assign streams for each approach as the below table:
| Methods | Kernel | metadata | Journal | Primary Index | Collection | 2nd Index |
|---|---|---|---|---|---|---|
| Original | 0 | 0 | 0 | 0 | 0 | 0 |
| File-based | 0 | 0 | 1 | 3 | 2 | 3 |
| Boundary-based | 0 | 0 | 1 | 4, 5 | 2, 3 | 4, 5 |
| DSM | 0 | 0 | 1 | 1 | 2, 3, 4 | 5, 6, 7 |
Note that updates to kernel are assigned with streamID 0 as default.
Workloads. We use YCSB with 23 million documents and Linkbench with maxid1 set to 80 million. To vary the write intensive, we config the benchmarks as below:
- Y-Update-Heavy: YCSB workload A.
- Y-Update-Only: YCSB only update operation
- LB-Original: Original Linkbench configuration
- LB-Mixed: Modified Linkbench with mixed Create, Update, Delete operations.
- LB-Update-Only: Modified Linkbench with only Update operation.
Experiment Resutls
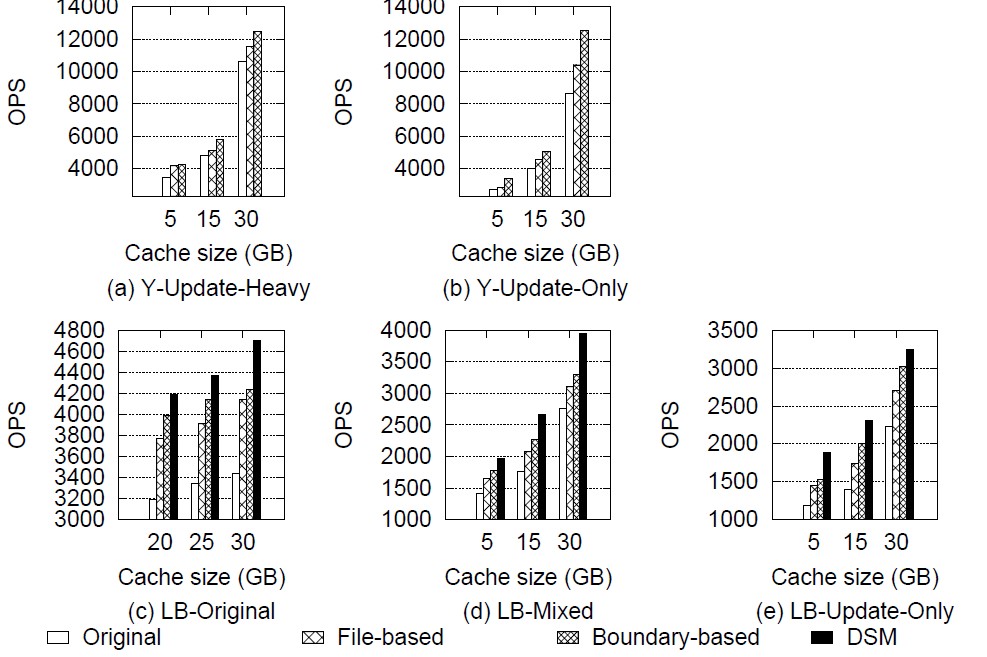
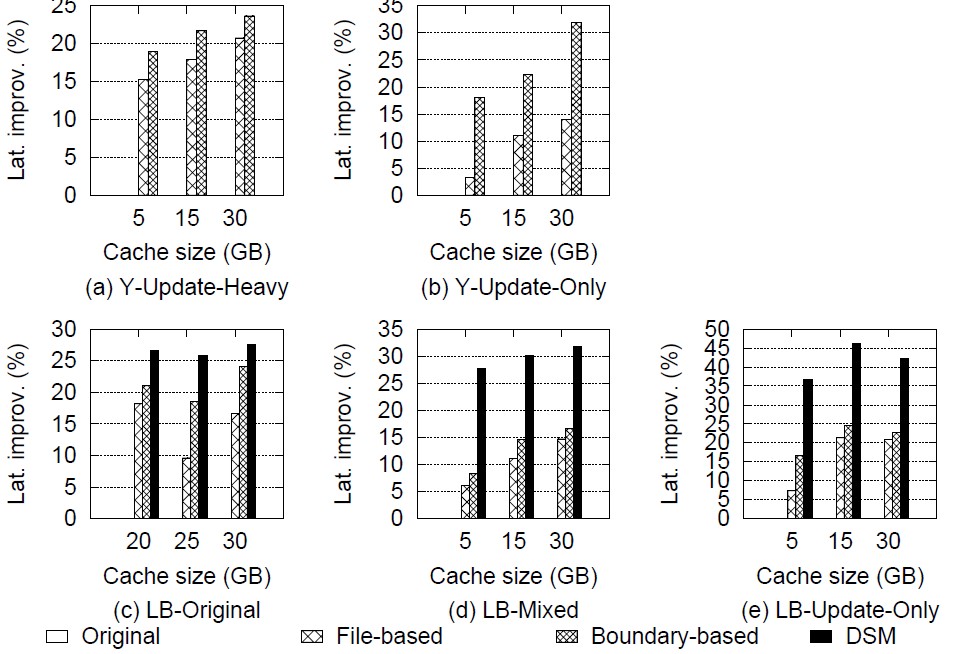
Below table summary the maximize output from the experiment results.
| Metric | File-based | Boundary-based | DSM |
|---|---|---|---|
| YCSB throughput | +19% | +44% | N/A |
| YCSB avg 99th lat | -20% | -32% | N/A |
| Linkbench throughput | +24% | +43% | +65% |
| Linkbench avg 99th lat | -20% | -24% | -46% |
Note that YCSB benchmark include one collection and one primary index. Moreover, all YCSB workload only update the collection file. Therefore, we don’t include the result of DSM in YCSB benchmarks.
Take-away Keys
- Multi-streamed SSD allows application group data with similar frequency access into one NAND block that could reduce the overhead of erase operation.
- File-based stream mapping is the simples but ineffective approach.
- Boundary-based stream mapping assigns streamID for two regions of each file seperated by a boundary. It solve data fragmentation between regions but inadaque to solve data fragmentation inside one region.
- Dynamic stream mapping assigns streams based on region’s hotness value. It solve data fragmentation inside one region.